2026-04-16
Opus 4.7 发!这两件事你必须知道,每天用 Claude 的赶紧看
Opus 4.7 十分钟前发了。 两件事 Anthropic 没写在通稿里。 一件让你这个月 API 账单悄悄多 17.5%。 另一件让你在某个场景里,选错模型。 两件都在 benchmark 表第二页。 SWE bench Verified 从 80.8% 涨到 87.6%。6.8 个点,在 agentic cod…
Opus 4.7 十分钟前发了。
两件事 Anthropic 没写在通稿里。
一件让你这个月 API 账单悄悄多 17.5%。
另一件让你在某个场景里,选错模型。
两件都在 benchmark 表第二页。
§ 一 · 进步是真的
SWE-bench Verified 从 80.8% 涨到 87.6%。6.8 个点,在 agentic coding 场景不算小。做 coding agent、做 dev tools 的副业人,这个数字落到你每天写代码里,体感能摸到。
Scaled tool use 77.3% · 对 GPT-5.4 的 68.1% 领先 9 个点。跑 agent pipeline 的,每次工具调用的成功率会好看一些。
视觉翻倍,支持 2,576px / 3.75MP 图片。做图片分析、小红书识别、产品截图理解的用得上,其他人意义不大。
还新增了 xhigh effort level · 推理的时候更舍得烧 token 换深度。
定价呢 · $5/$25 per million tokens,跟 Opus 4.6 挂牌价一个字没改。
又强又没涨价,Anthropic 这次挺厚道的。
我一开始也这么想。
§ 二 · 退步他没说
BrowseComp · Opus 4.6 是 83.7,Opus 4.7 是 79.3。
BrowseComp 测的是 AI 打开浏览器找信息 · 搜、读、判断、给答案。就是你做 deep research、做 AI 搜索,每天让模型干的那种活。
这一项 Opus 4.7 退了 4.4 个点。
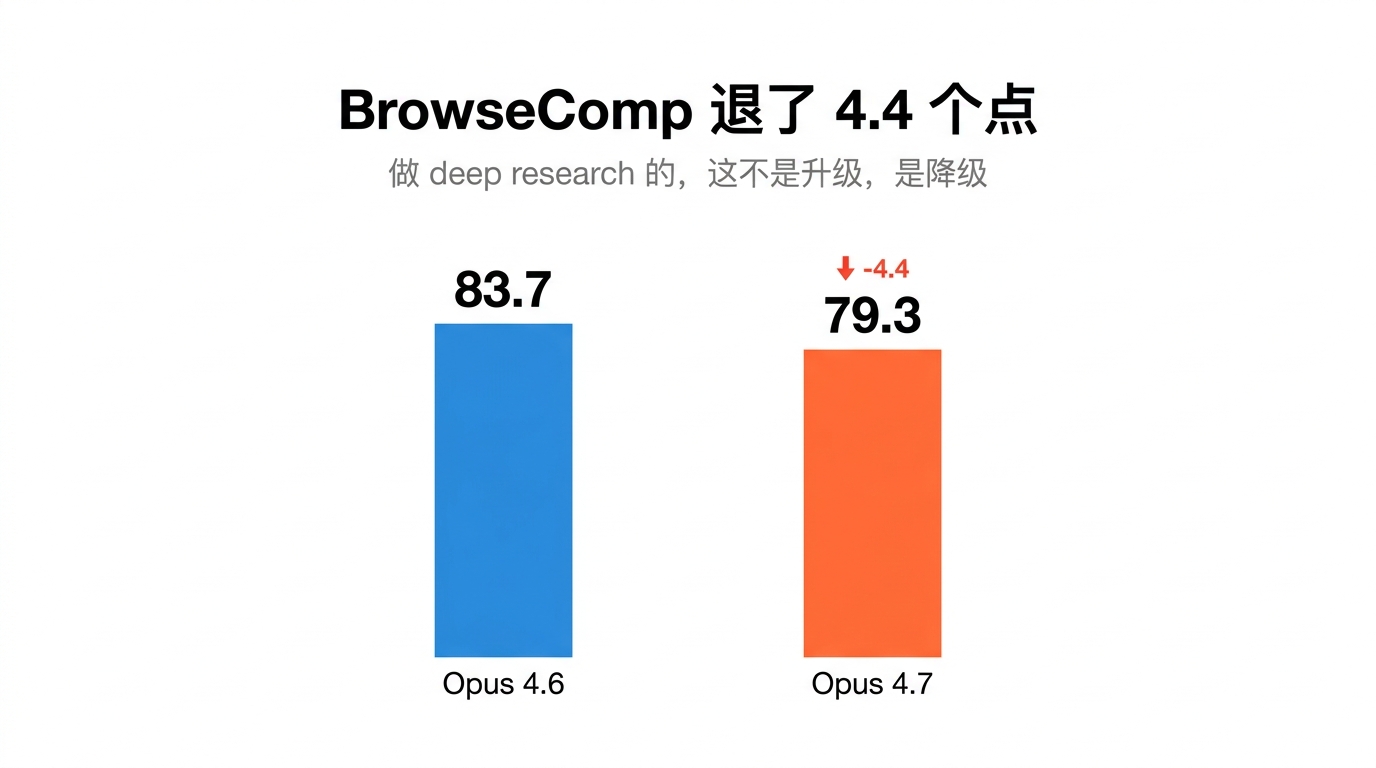
Anthropic 发布通稿里没有这一行。进步列了一堆,这项没提。
为啥退 · 官方没解释。我猜 · 算力和数据倾斜给了 coding,浏览能力没跟上。也可能测试集本身变了。但变了的话官方得说一声。
不猜也行。结论反正不变 · 做搜索、做 deep research 的,Opus 4.7 对你不是升级,是降级。
4.4 个点在你实际工作里是什么感受 · 十次搜资料,以前答不到点子上 2 次,现在 3 次。做 AI 搜索的,用户体感立刻下降一档。
最骚的不是退步。退步这种事 AI 升级里从来都有。
最骚的是 · 这一行白纸黑字写在 Anthropic 自己的 benchmark 表里,但发布通稿一个字没提。
这不是藏。是挑着说哪些给你看。
§ 三 · 挂牌价没动,钱包在动
挂牌价 $5/$25 per million tokens · 跟 4.6 一个字没改。
但你这个月底的账单,会多。
Anthropic 动手脚的地方不是价签,是计价器。出租车司机没改起步价 · 他改的是计价器。同样的路,表上读出来的钱比以前多。
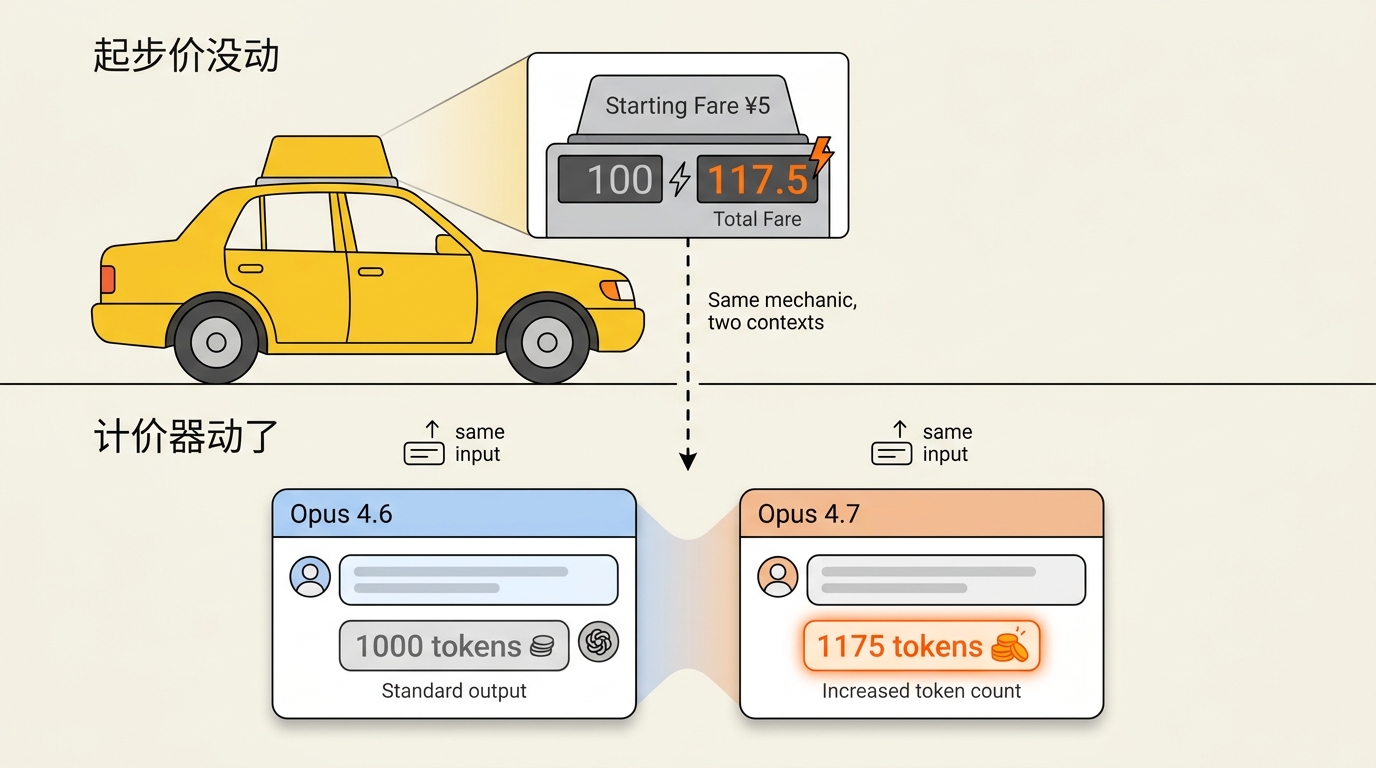
他们动的是 tokenizer · 模型把你输入切成 token 的算法。同样一段中文、一段代码、一段 HTML,Opus 4.7 会切出比 4.6 更多的 token。Anthropic 官方原话 · 「同等 input 多消耗 1.0-1.35x token,取决于内容类型」。
取中间值 1.175x · 你付的钱比以前多 17.5%。
3 档你自己对号:
| 月 input 用量 | 原来花 | 现在花 | 多花 |
|---|---|---|---|
| 100 万 token(轻度) | $5.00 | $5.88 | $0.88 |
| 1000 万 token(中度) | $50.00 | $58.75 | $8.75 |
| 1 亿 token(重度) | $500.00 | $587.50 | $87.50 |
单月看小,年看不小。重度用户年下来多花好几百刀。
做 agentic pipeline 的最伤 · 每次 agent 调用都塞完整上下文,每次 tool call 都吞 input · 17.5% 在长 pipeline 里会叠加。年度多花几千刀不奇怪。
影响最大的是两类人 · 一是 content creator(处理一堆自然语言),二是 scraping + summarization pipeline(吞一堆 HTML,符号密度高,接近 1.35x 上限)。纯代码用户影响最小,接近 1.0x。
最骚的是 Anthropic 怎么讲这件事。
挂牌价没动,技术博客里轻轻带一句「tokenizer 升级」,当它是一个技术改进。
「实际成本涨了 17.5%」这七个字 · 没出现过。
Anthropic 这家公司常年讲「诚实」。这个表达方式算不算诚实,你自己品。
他们同一时刻还发了一个 Mythos Preview。据说强到自己不敢公开卖,只给 40 家顶级安全合作方用,挂牌价是 Opus 4.7 的 5 倍。
戏剧性挺大。但你买不到也用不上。
真正动你钱包、改你选型的,就前面这两件事。
§ 四 · 今天选哪把刀
做 coding 的、跑 agentic pipeline 的,你升 4.7。SWE-bench 从 80.8 到 87.6 是真的,tool use 对 GPT-5.4 领先 9 个点也是真的。这场景 4.7 值得升,tokenizer 涨 17.5% 你硬吞 · 能力提升对得起这个钱。
做搜索的、做 deep research 的,别升 4.7。BrowseComp 退 4.4 个点已经告诉你答案了,留 4.6 更稳。或者切 GPT-5.4 · 对,这次发布最反直觉的一件事就是这个 · search 场景 GPT-5.4 比 Opus 稳。
做批量内容、翻译改写、轻量文案的,Opus 根本不在你的候选名单里。太贵。Sonnet 4.6 或 Gemini 3.1 Flash,每 million token 便宜一个数量级,足够用。
「一个最强的模型」这件事,在 2026 年已经不成立了。
coding 用 4.7。search 用 GPT-5.4。批量用 Sonnet 或 Flash。

三把刀,别想用一把砍全场。
收尾
Opus 4.7 是执行力升级。
只是这次升级,Anthropic 告诉你它变强了 · 没告诉你它在某些场景变弱了,也没告诉你你的账单变高了。
模型升级这件事,从今天起不是单向的。你得自己翻 benchmark,自己算账单,自己决定哪个场景用哪把刀。
「最强的模型是哪个」 · 这个问题往后越来越难答。因为最强的那个,他们不卖给你。你能买到的,一个强一点弱一点,一个贵一点便宜一点,一个会搜不会写,一个会写不会搜。
挑刀的时候到了。